Linear Models(4) - Logistic Regression
2021. 3. 7. 15:38ㆍ[AI]/Machine Learning
Learned Stuff
Key Points
- Train / Validation / Test
- Accuracy Score
- Logistic Regression
- Baseline Model
- Predictive Model
New Stuff
[Train / Validation / Test]
- Train data로 학습시킨 모델을 Validation data을 써서 검증을 진행한다
- 위 과정을 여러번 반복해서 최적의 모델을 만들어야 한다
- Test data는 마지막 단계에서 예측용으로 쓴다
code
# train / validation / test data를 6:2:2 비율로 나누기
from sklearn.model_selection import train_test_split
# df 라는 DataFrame이 있다고 가정
# train / test data를 8:2 비율로 나눈다
train_df,test_df = train_test_split(df,test_size = 0.2,train_size=0.8,random_state = 42)
# test_size : test data 비율
# train_size : train data 비율
# random_state : 임의로 지정
# train / validation data를 6:2 비율로 나눈다
train_df,validation_df = train_test_split(train_df,test_size=0.25,random_state = 42)
# test_size 을 지정해주면 train_size 는 알아서 계산이 된다
[Accuracy Score]
- 예측값과 실제값이 얼마큼 같은지를 보여주는 지표
code
from sklearn.metrics import accuracy_score
# y_train : training data의 label 값
# y_pred : 예측한 label 값
accuracy_score(y_train, y_pred)
# ==> returns accuracy score between prediction & label values
[Logistic Regression]
- target variable 이 categorical data일 때 주로 쓰인다 (ex. disease 걸렸다 /안 걸렸다)
- Regression 이란 명칭을 쓰지만 Classification에 더 가깝다
- class가 3 이상인 target variable에도 쓸 수 있다
- class가 2개일 경우 아래 그림과 같이 0.5 이상이면 1로 간주 / 0.5 이하면 0 으로 간주한다
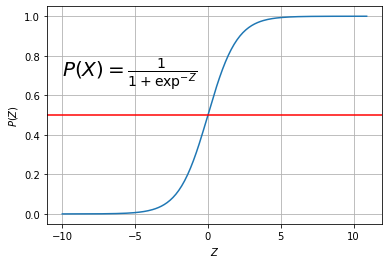
-
Logistic Regression Equation
-
$P(Z(X))={\frac {1}{1+e^{-Z(X)}}}$ , $Z(X) = -(\beta_{0}+\beta_{1}X_{1}+\cdots +\beta_{p}X_{p})$
- (괄호 안쪽 부분은 Multiple Regression 과 같음)
-
$ 0 \leq P(X) \leq 1$
-
Baseline Model
- most frequent target variable을 기준으로 model을 만든다
code
# y_train 이라는 DataFrame이 있다고 가정
# 가장 빈번하게 나온 target 값 담기
most_frequent_target = y_train.mode()[0]
# y_train의 길이에 맞게 list로 만들어주기
y_pred = [most_frequent_target] * len(y_train)
accuracy_score(y_train, y_pred)) # accuracy 확인
Predictive Model
- model을 만들고 예측을 한다
code
from sklearn.linear_model import LogisticRegression
# X_train / y_train / X_test / y_test 라는 DataFrame이 있다고 가정
logistic = LogisticRegression()
logistic.fit(X_train,y_train)
logistic.score(X_test,y_train) # test data에 대한 accuracy 반환
728x90
'[AI] > Machine Learning' 카테고리의 다른 글
| Linear Models(2) - Multiple Regression (0) | 2021.03.07 |
|---|---|
| Linear Models(3) - Ridge Regression (0) | 2021.03.07 |
| Tree Based Model(1) - Decision Trees (0) | 2021.03.07 |
| Tree Based Model(2) - Random Forests (0) | 2021.03.07 |
| Tree Based Model(3) - Evaluation Metrics for Classification (0) | 2021.03.07 |